Why We Don't Use HNSW For Agent Memory Search
Standard vector databases lean on knowledge graphs and parallel pipelines to compensate for HNSW's approximate search. Information-Theoretic Scoring removes the need for both, and matches hybrid systems on every public benchmark.
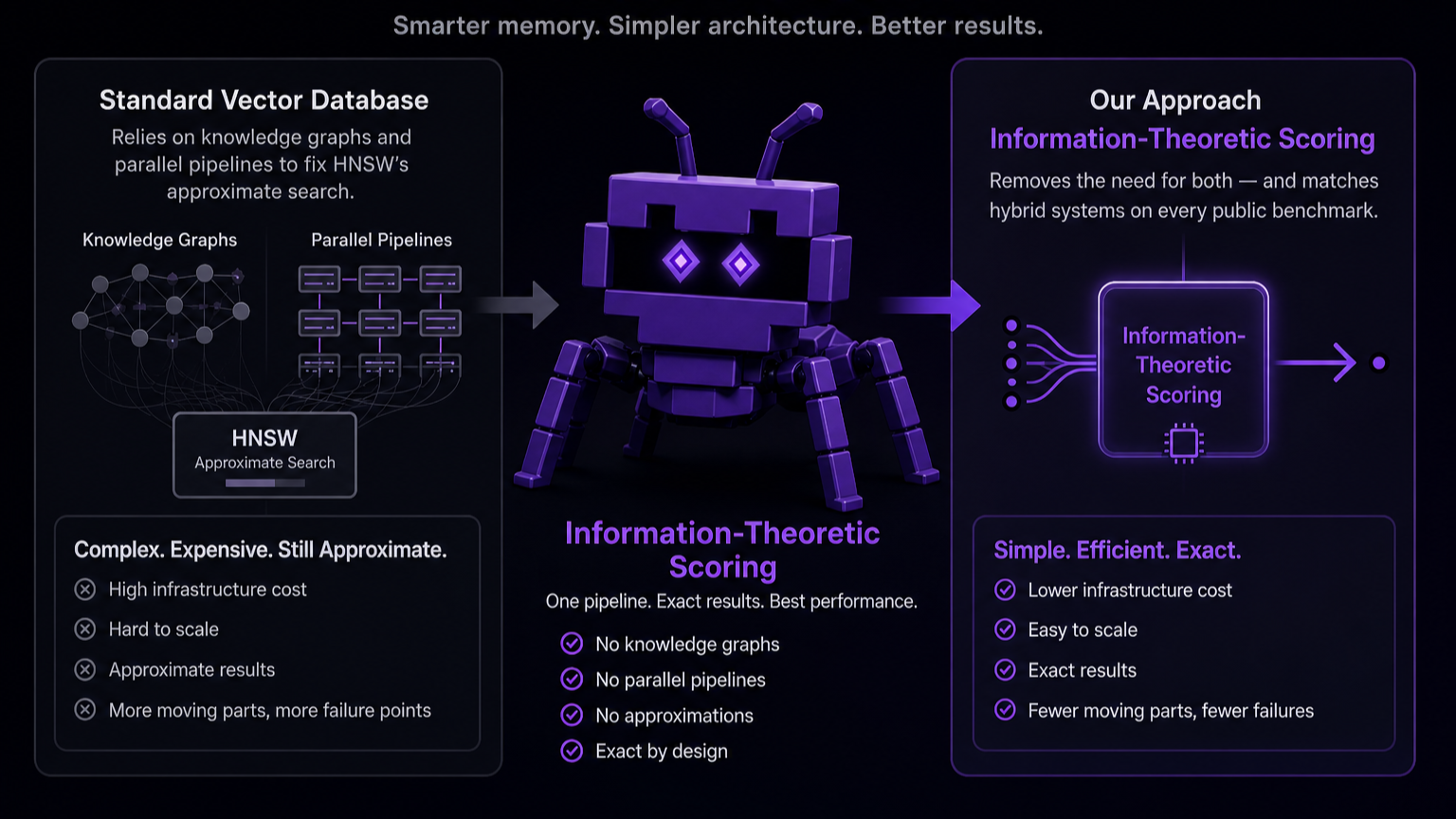
The transition from stateless LLM interactions to persistent, multi-session autonomous agents has revealed memory to be a primary architectural bottleneck. In response, the industry has largely converged on a standard paradigm: augmenting traditional vector databases with complex Knowledge Graphs and multi-query recursive pipelines.
While hybrid systems are undeniably powerful, they introduce substantial computational overhead. When we set out to build Memanto, our memory agent for long-horizon agents, we decided to step back and re-examine the foundation. We asked a fundamental question: Is the complexity of graph traversal strictly necessary, or is it a workaround for the limitations of geometric vector search?
By moving away from standard in-memory HNSW and Cosine distance stacks in favor of Information-Theoretic Scoring (ITS), we found that addressing the core retrieval bottleneck at the semantic layer provides a highly scalable alternative to hybrid orchestration.
Here is why we don't use traditional vector databases for agent memory, and why Information-Theoretic Scoring represents a shift in how we handle long-term agentic context.
The Bottleneck in Agentic Memory Retrieval
To understand why the current paradigm leans so heavily on graph databases, we have to look at how standard architectures handle conversational data.
- The HNSW "Approximate" Penalty: Standard vector databases rely on HNSW (Hierarchical Navigable Small World) indexes to search across float32 vectors efficiently. However, HNSW is an approximate nearest neighbor (ANN) algorithm. When searching for highly specific, needle-in-a-haystack conversational fragments, "approximate" means the database can (and often does) completely skip the exact chunk you need simply because it didn't fall perfectly along the graph edges the algorithm traversed.
- The Graph Workaround (and its Ingestion Tax): Because vector embeddings map semantic similarity rather than explicit logic, standard RAG can sometimes struggle with multi-hop reasoning (e.g., connecting "I work at Acme" in Session 1 with "My company uses AWS" in Session 5). To solve this, the industry adopted Knowledge Graphs to explicitly map these relationships (
User -> works for -> Acme -> uses -> AWS). However, this introduces a staggering ingestion tax. Every time a memory is saved, an LLM must be invoked to extract entities and define edges to update the graph, creating a compute-heavy synchronous process that burns tokens and introduces latency on every single write operation. - The Parallel Retrieval Patch: To further compensate for the limitations of approximate vector search, hybrid frameworks began wiring together complex parallel retrieval pipelines. When an agent needs to remember something, the system simultaneously fires queries across the vector database, a keyword search engine (like BM25), and the knowledge graph. It then has to merge and re-rank these disparate results. This attempts to patch the foundational retrieval problem with architectural brute force, introducing significant latency and operational overhead on the read path.
- The Multi-Query LLM Tax: Compounding the read-path latency is the reliance on complex query orchestration. Because a single geometric query often fails to surface all relevant graph nodes or vector chunks, frameworks rely on an LLM as a middleman during retrieval. Sometimes this means generating 5-10 variations of the agent's prompt to run in parallel, other times it means recursive prompting where the LLM repeatedly queries the database in a loop until it thinks it has enough context. In either case, it requires another LLM step (or cross-encoder) to synthesize and rerank the final results, creating a massive token and latency tax on every single retrieval.
What Information-Theoretic Scoring Actually Is
The traditional vector database stack relies on HNSW + float32 vectors + cosine similarity, which requires huge amounts of expensive RAM to hold the index. Instead of relying on graph workarounds, we built Memanto on top of Moorcheh's Information-Theoretic Search (ITS) engine.
Moorcheh replaces the standard float32 stack with Maximally Informative Binarization (MIB) and Information-Theoretic Scoring (ITS). By compressing high-dimensional vectors into compact binary representations (achieving a 32x compression ratio), the engine can perform incredibly fast bitwise distance calculations.
Why does this matter for agent memory? Because it allows the engine to perform deterministic, exhaustive search over the entire dataset in sub-90 milliseconds. It doesn't rely on approximate graph traversal (HNSW), meaning it doesn't randomly miss critical chunks.
By fixing the retrieval bottleneck at the foundational level, ITS allows us to systematically strip away the architectural bloat that plagues modern memory frameworks:
- Replacing Knowledge Graphs with Deterministic Search: One of the primary reasons the industry adopted knowledge graphs was because HNSW's approximate search couldn't be trusted to reliably surface connected conversational fragments. Because Moorcheh's exhaustive search is deterministic, it finds those exact fragments every single time. This eliminates the need to map explicit relationships in a graph, allowing us to ingest raw conversational chunks instantly and bypass the LLM ingestion tax entirely.
- Dynamic Context Scaling: When memory layers want to dynamically size their retrieval window to avoid blindly grabbing unnecessary chunks, they frequently have to rely on an LLM to evaluate relevance or determine when to stop expanding the search. Instead, Moorcheh has a native Information-Theoretic Reranker to dynamically size the final context window based on actual density and relevance. We grab the exact section of the haystack that matters without the latency of an LLM routing step.
- Bypassing the Parallel & Multi-Query Patch: Modern LLMs (like Gemini 3) are highly capable of filtering noisy context, provided the critical information is actually present. By feeding the LLM a wider runway of deterministically-ranked chunks, we eliminate the need for parallel BM25 searches and multi-query prompt generation. We use a single query on retrieval, and the LLM acts as the final synthesizer. As foundational models continue to improve their long-context reasoning capabilities, the reliance on external graph databases to explicitly map relationships will only diminish further. The LLM itself is the ultimate reasoning engine, our job is just to surface the right fragments reliably.
Empirical Validation: ITS vs. Hybrid Architectures
To validate this approach, we benchmarked Memanto against leading memory frameworks using the LongMemEval and LoCoMo datasets. We ran these benchmarks using Gemini-3.
| System | LoCoMo Score | LongMemEval Score | Memory Architecture | Uses LLM on Write |
|---|---|---|---|---|
| Hindsight | 89.61% | 91.4% | Hybrid (Graph + Vector) | Yes |
| Memanto | 87.1% | 89.8% | ITS-Based Vector | No |
| EmergenceMem | — | 86.0% | Hybrid (Graph + Vector) | Yes |
| Supermemory | — | 85.2% | Hybrid (Graph + Vector) | Yes |
| Memobase | 75.8% | — | Hybrid (Graph + Vector) | Yes |
| Zep | 75.1% | 71.2% | Hybrid (Graph + Vector) | Yes |
| Full context | 72.9% | 60.2% | Full Context | N/A |
| Mem0 G | 68.4% | — | Hybrid (Graph + Vector) | Yes |
| Mem0 | 66.9% | — | Vector Only | Yes |
| LangMem | 58.1% | — | Vector Only | Yes |
Despite having no explicit graph traversal and relying solely on a single retrieval query, Memanto achieved 89.8% on LongMemEval and 87.1% on LoCoMo.
While a select few highly tuned parallel-retrieval frameworks post slightly higher numbers, this performance jump highlights a broader architectural trend: the industry's reliance on increasingly complex pipelines to squeeze out incremental gains. Achieving those final few percentage points currently involves a significant trade-off, invoking an LLM on every write operation to build and maintain a knowledge graph. For use cases where absolute maximum accuracy is required regardless of compute costs or write-latency, this heavy hybrid approach remains highly effective.
However, Memanto's results demonstrate that such complex architectures may not always be necessary. Pure semantic retrieval is far more capable than the industry currently assumes. By shifting from geometric scoring to Information-Theoretic Scoring, developers can achieve an accuracy baseline that outperforms the vast majority of hybrid systems, while entirely eliminating the LLM ingestion tax and drastically simplifying operations.
Scaling Agentic Memory
The next phase of agentic AI will not be won by the most complicated memory diagram. It will be won by architectures that can deliver reliable, long-horizon reasoning without crippling compute costs or production latency.
For the last year, the industry has operated under the assumption that achieving state-of-the-art agent memory requires the complexity of a knowledge graph and the overhead of parallel retrieval pipelines. Memanto proves this assumption wrong.
By shifting away from the geometric limitations of HNSW and adopting Information-Theoretic Scoring, developers can build agents that rival state-of-the-art hybrid systems in accuracy, but with zero write-path LLM tax, no graph schemas to maintain, and a simple, single-query retrieval architecture.
The path forward for scalable agentic memory isn't adding more orchestration layers to compensate for broken search. It's fixing the search.
Reproducibility
We encourage the community to verify these results and explore the architecture:
- Read the paper: Memanto: Typed Semantic Memory with Information-Theoretic Retrieval for Long-Horizon Agents (arXiv:2604.22085)
- Run the benchmarks: Our evaluation suite is fully open source. You can find the code, benchmarks, and instructions to reproduce these results in the memanto-evaluation repository.
- Interactive Evaluation: Test and reproduce our benchmarks directly using our Interactive Evaluation dashboard.